Cross Validation Strategies
High Level Idea
During my career as a Data Scientist, I’ve learned there are a multitude of strategies for cross-validation, and that each have their time and place. Pictured below is an overview of what we’ll be discussing in this blog post.
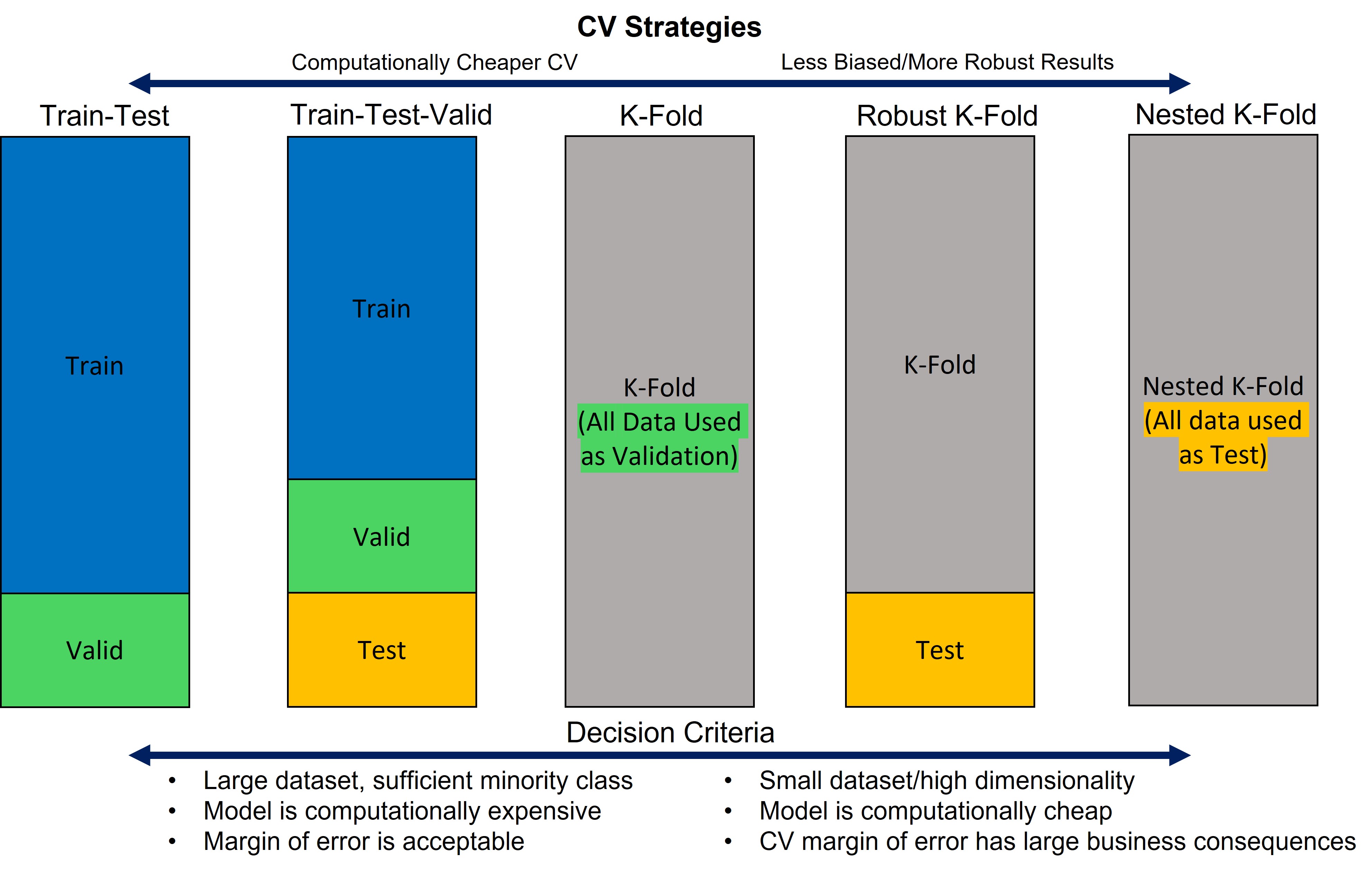
If it looks a bit confusing, don’t worry! At the top of the graphic we have the benefits of the various strategies, and the bottom we have the situations that would lead you to lean toward various strategies. Upon explaining the various strategies it will serve as a great high-level overview of the pros, cons and decision criteria that should be considered when choosing a cross validation strategy. We will explain all of the CV strategies, and then discuss a few use cases and why you would use one over the other.
CV Methods
Train-Test and Train-Test-Valid Split
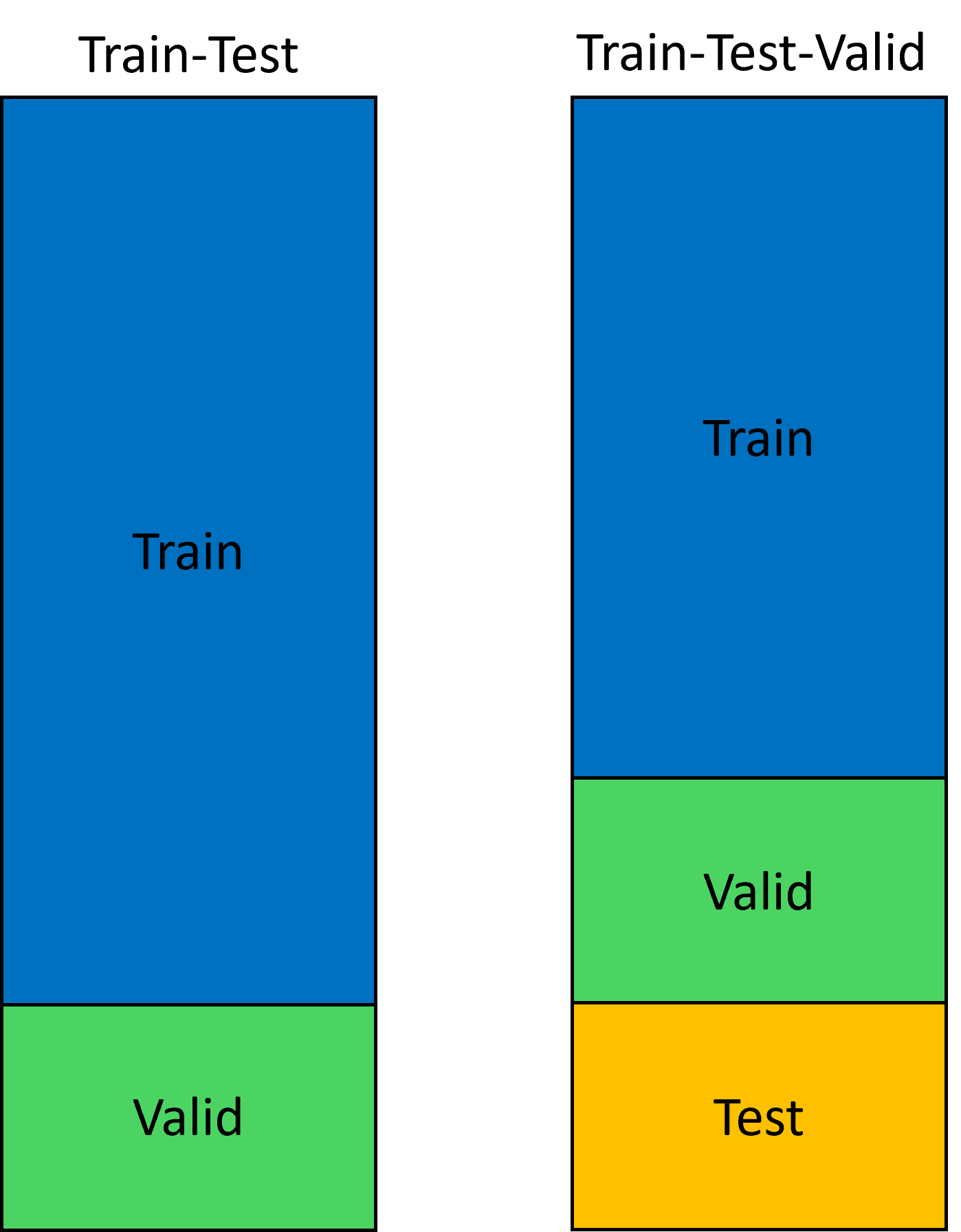
Train-Test
The most simple cross-validation strategy, one portion of the data is used for training and selecting hyper-parameters, and a portion is used to validate the performance of the model.
Pros:
- The most computationally cheap strategy
- (Great for large datasets and computationally expensive models)
Cons:
- Prone to Bias
- Bad for small datasets with high dimensionality
Train-Test-Valid
The second most simple cross-validation strategy, again we use the train and valid iteratively to select the best hyper-parameters. Here we have an additional test set, to see the performance of a model that hasn’t seen this data in any portion of the modeling process. Generally a better option than Train-Test due to less bias, but with slightly less data for training and validating.
K-fold CV
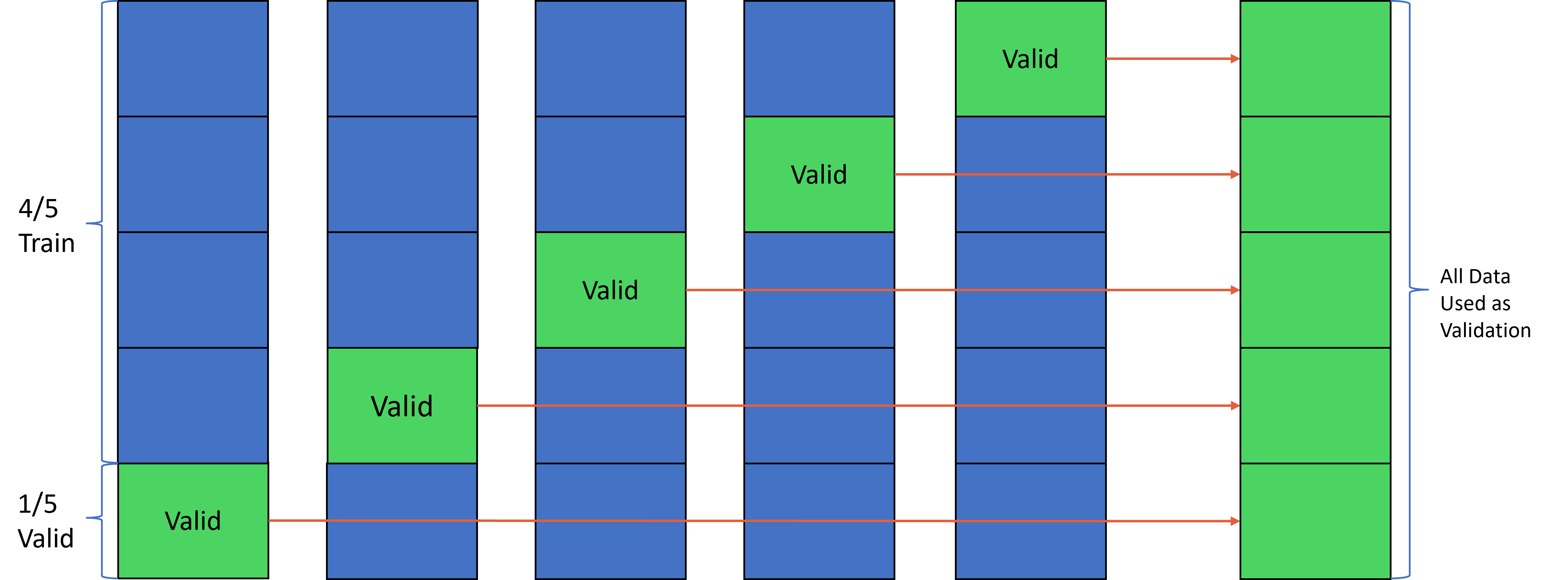
A middle of the road approach concerning the techniques referenced here. We pick a k, (5 in this example, 10 is more common), and run the whole process k times, using a different 20% (1/k) of the data as a validation set each time. Then we combine these 5 parts, and we have an estimate for the performance of the model, using every datapoint instead of just the Valid portion. This is now 5 times more computationally expensive than our previous methods but gives us a much larger sample of data to validate our results on.
Pros:
- Less biased results than a regular Train-Test split.
Cons:
- Somewhat computationally expensive (k* more expensive).
Robust K-fold CV

We use 80% of the data for k-fold cross validation, and save 20% as a test set that the process has not seen yet. Similar to K-fold, but with slightly less data available for the K-fold process and slightly less bias.
Nested K-fold CV
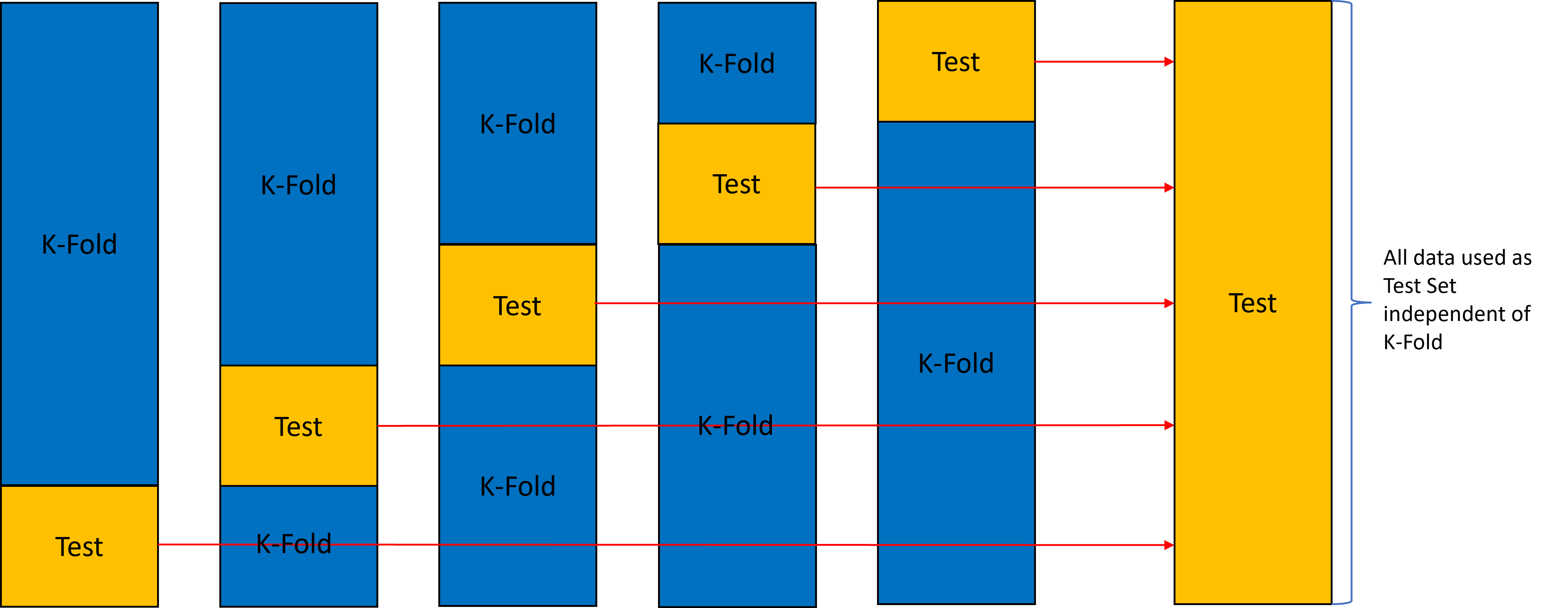
Here we repeat this entire K-fold process 5 times (for k=5), so that we have a test set score independent of the K-fold procedure for every data point.
Pros:
- Extremely unbiased estimate
Cons:
- K times more expensive than K-fold, k^2 more computationally expensive than Train-Test.
- Is unrealistic for computationally expensive applications as a training loop may take weeks.
- In the given time we can train less hyper-parameters.
Use cases:
Train-Test-Valid (Or Train-Test)
- Situation: We are doing image classification with a massive dataset with millions of rows.
- Explanation: The model is computationally expensive making K-fold unrealistically long to compute results, and due to the dataset size, the chances of bias due to a bad test split is extremely low. I prefer Train-Test_Valid
Nested K-Fold
- Situation: We have a small tabular dataset, with large dimensionality, and extremely high business impact for each decision.
- Explanation: Small tabular dataset means the modeling computational cost is low and Nested K-Fold will still be light on computing power even with a computationally expensive CV procedure. High business impact means we want as accurate an estimation of the performance as possible.
Robust K-Fold (Or K-Fold)
- Situation: We have a medium sized dataset, and still want to be careful to avoid bias and accurately represent performance. (Middle of the road)
- Explanation: A dataset of a few hundred thousand rows being trained with a K-Fold CV will not be unreasonably computationally expensive. The results are still very robust and unbiased. Good middle of the road solution. I prefer Robust K-Fold generally.
Closing Thoughts
I took my time putting this together as I feel its a nuanced discussion that doesnt always have perfect answers. Some of your choices will come down to practical considerations, and some down to how you personally weight the pros and cons of each strategy. This was by no means an exuastive list of CV strategies or factors that can influence these decisions, but I hope its serves as a concise high level view of the topic.