Random Forests, An Artifact of good timing?
From early on in my datascience career(2017) I have been a big fan and advocate of tree-based algorithms. The flexibility of input and target variable distributions, paired with astounding results made me come back to them again and again for a variety of problems. Everything from classification to NLP they are a great tool to get your project going.
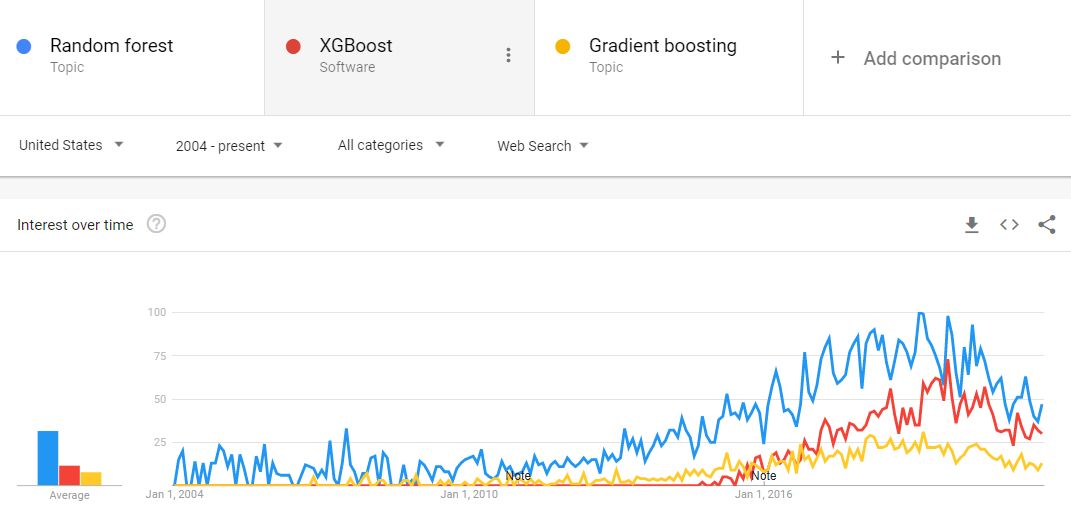
The first algorithms in my data-science journey were random forests and elastic-net regression, then eventually GBMs, and then XGBoost, CatBoost etc.. Without fail the GBMs and eventually XGBoost would outperform the random forests and I repeatedly assumed that this individual problem just fit boosted algorithms better. However, after enough experience, I strated to think that perhaps random forests were simply an inferior algorithm and I wondered why they are so dominant in the field of datascience? Well perhaps its simply because they were around first.
The first algorithm for random decision forests was created in 1995 by Tin Kam Ho. The first GBMs proposed by Jerome Friedman, in his seminal paper in 1999 (updated in 2001).
Analytics
Is there any other evidence we can garner for this assertion? Google trends (take them with a grain of salt) lets us see there was a time when GBMs were almost non existent in searches while Random Forests were being searched quite regularly, and with time, for good reason, this is changing.